Ps and Qs: Textual Analysis of UK Rap Scene
UK rap music prides itself on lyricism; wordplay, themes, and multitiered rhyme schemes. These components of a rap song are just as important as the beat. There is much emphasis on what is being said; it could be an insult, reference to pop culture or a callback to someone in the rap-scene. This focus on words is a big part of grime and the best lyrics can earn an artist a wheel-up (or 3).
As a result, I thought it would be interesting to have a look at the words behind the UK Rap scene. This post won’t contain any code snippets (happy to share if anyone is interested). First we will look at some descriptive statistics relating to the contribution of each artist to the scene, before doing some natural language processing activities.

The Data Set
Genius is a go-to for lyrics and understanding the multiple meanings of some lines. They kindly provide an API through which to access this wealth of information. Using the API we can pull lyrics from any given artist. I created a list of UK rappers and queried the API, this process took a long time as not to overload the server with requests. I understand there may be some artists missing, so please let me know if you’d like to see anyone else in there! The data used contains all lyrics on LyricGenius related to the selected artists shown in the pie chart below. Contains 4742 songs from 45 artists containing 2,220,363 words.
The interactive chart shows contribution of songs by each rapper to this data set. Immediately we can see how productive Wiley has been, over 100 more songs than Ghetts. Other leading contributors include the old guard of Giggs, Kano and the once new kid on the block: Chip. M.I.A. is another veteran of the scene and contributes a similar amount to Skepta, Dizzee Rascal and JME. Bugzy Malone and Little Simz have the biggest contribution of the newer rap artists. By no means is this the definitive list of UK Rap contributions, this list is obtained from lyric genius and although it does a good job of posting freestyles and mixtapes - there will be some lyrics not posted.

Lyrics for Lyrics
Since song contributions looks more like a timeline of the rap scene, maybe a look at the words within the songs may help. The chart below looks at unique words; showing the average number of unique words per song on the y axis and the average number of words per song on the x. Moving up towards the top of the chart shows more unique words used in a song. Whereas moving rightward shows there are more words in a song. Size of the bubbles indicates the number of songs, this provides a good indication of sample size e.g. Mike Skinners solo effort only contains 1 song whereas The Streets have 119.
The trend is expected: as you say more words in a song you are bound to use more different words, therefore move to the top right of the graph. Two artists on the top right (Mic Righteous and Dave ) are packing a lot of different words into their songs. This could be used as a measure of lyricism, they are 2 artists certainly knows for their lyrics. Not too far behind them are a selection of known wordsmiths: Cadet, Bugzy Malone, P Money, Lowkey, and Akala. Towards the bottom left of the chart we have the less wordy rappers, MIA and MIST have 126 and 142 unique words per song on average.
Where do you know me from?
Representing your city or area is an element of rap culture. Especially as the scene expands further out of London; area codes make good ad-libs. Geo-encoding is the method of extracting place names out of text. Using all lyrics in the data set, place names have been extracted. London is by far the most talked about place in the grime scene. In fairness, it has had a head start advantage as in the early days a lot of the scene was based in London therefore lot’s of rappers were talking about London, so much so that even East London makes the top 5. There is also references to Meridian Estate in Tottenham, where a lot of the original grime MCs were from. Nice is picked up a lot in the lyrics, but I don’t think artists were referring to the area in France. A good example of the shortfalls of working with language and textual data, and why context is important.
What you saying?
A large part of working with language dat is the cleaning of it; data must be cleaned, removing stop words and making sure all words are lower case. In this particular instance, it also meant censoring expletives, of which there were many different kinds.After this we can produce a word cloud, this is an image showing the most popular words in UK Rap lyrics, the size indicates the frequency of that word.
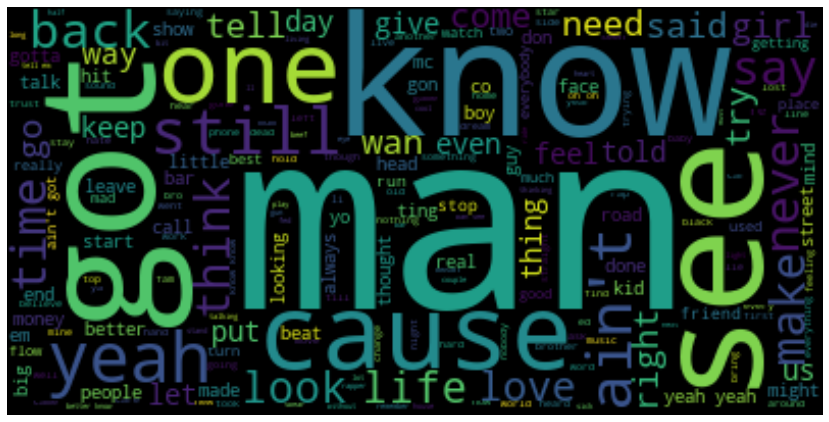
Initial reaction to the output is that the UK rap scene is very knowledgeable and male dominated. Stormzy does have a song titled “Know Me From” which uses Know multiple times. The word cloud is mostly comprised of rap slang, these words are pretty good for keeping the flow going as well, so no surprised they are commonly used by all rappers.
I hope you enjoyed a different view of the UK Rap scene. Using the Genius API to create aggregate statistics of the scene showed some the dominance old rappers have in terms of output. A look into the uniqueness of words used by each artist also hints at the lyrics heavy weights. This type of analysis can be applied to other music genres and locations such as hip-hop…
Thanks for reading!

Bonus: Topic Modelling
Whilst wordclouds provide a nice visual representation of frequency, they are often plagued with stop words and it is difficult to ascertain meaning forth result. Throughout the article we have been cleaning the textual data, to such an extent we can now embark on topic modelling.
Topic modelling is an unsupervised machine learning technique which seeks to find a group of words (topic) from a series of documents (songs). In this case, pyLDAvis is utilised to perform the topic grouping and create the visualisation. This library employs the Latent Dirichlet Allocation (LDA) algorithm, at a high level the algorithm examines how words (and phrases) co- occur. If words that appear often in close proximity are assumed to represent a topic. LDA is a Bayesian approach, and uses Dirichlet priors. It treats documents (songs) as probability distributions over topics and topics as probability distributions over words. I think its a really cool approach to topic modelling and widely used as it generalises well, you can find a more in-depth explanation here.
The visualisation below is the output of the LDA - the circles represent topics, the words on the right are the words in that topic. Now some human intuition is needed to interpret the topic. Topic 10 provides an upbeat subject - shake, sauce, jest, rascal, and jump indicate the dancing side of UK rap, these may be the topics seen in the club tunes. Not all songs are for the club, Topic 1 is quite a positive one, about life, feeling, love, needs and people. It seems that the UK Rap scene has a sensitive side. As Kano said “This ain’t for the club, it’s for the mandem on the curb”. Have a click around the model and see what topics you can find!
